Conversations around data science typically contain a lot of buzzwords and broad generalizations that make it difficult to understand its pertinence to governance and policy. Even when well-articulated, the private sector applications of data science can sound quite alien to public servants. This is understandable, as the problems that Netflix and Google strive to solve are very different than those government agencies, think tanks, and nonprofit service providers are focused on. This does not mean, however, that there is no public sector value in the modern field of data science. With qualifications, data science offers a powerful framework to expand our evidence-based understanding of policy choices, as well as directly improve service delivery.
To better understand its importance to public policy, it’s useful to distinguish between two broad (though highly interdependent) trends that define data science. The first is a gradual expansion of the types of data and statistical methods that can be used to glean insights into policy studies, such as predictive analytics, clustering, big data methods, and the analysis of networks, text, and images. The second trend is the emergence of a set of tools and the formalization of standards in the data analysis process. These tools include open-source programming languages, data visualization, cloud computing, reproducible research, as well as data collection and storage infrastructure.
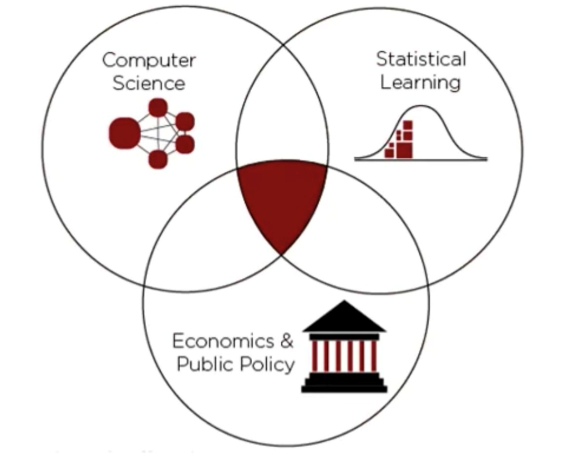
Perhaps not coincidentally, these two trends align reasonably well with the commonly cited data science Venn diagram. In this diagram, data science is defined as the overlap of computer science (the new tools), statistics (the new data and methods), and critically, the pertinent domain knowledge (in our case, economics and public policy). While it is a simplification, it is still a useful and meaningful starting point. Moving beyond this high-level understanding, the goal of this paper is to explain in depth the first trend, illuminating why an expanded view of data and statistics has meaningful repercussions for both policy analysts and consumers of that analysis.
Traditional evidence-building for policy analysis
Using data to learn about public policy is not at all new. The origins of the social sciences using statistical analysis of observational data goes back at least to the 1950s, and experiments started even further back. Microsimulation models, less common but outsized in their influence, emerged as the third pillar of data-driven policy analysis in the 1970s. Beyond descriptive statistics, this trifecta—experiments, observational statistical analysis, and microsimulation—dominated the quantitative analysis of policy for around 40 years. To this day, they constitute the overwhelming majority of empirical knowledge about policy efficacy. While recent years have seen a substantial expansion in the set of pertinent methods (more on that below), it is still critical to have a strong grasp of experiments, observational causal inference, and microsimulation.
The expanded methods of data science for policy analysis
Nothing discussed above falls outside the field of data science. These approaches all use data, programming, and statistics to infer meaningful conclusions about the world. Still, the term “data science” has some value, as it connotes a broader set of methods and data types than is traditional to the field of policy analysis. While many of these methods have existed for a long time, the proliferation of new and diverse data sources means this expanded toolkit should be more widely understood and applied by policy analysts. Many of the methods detailed below fall into the field of machine learning, but in this case, that terminology complicates the issue without adding much clarity.
Why data science matters to public policy and governance
Evaluating data is becoming a core component of government oversight. The actions of private companies are more frequently in databases than file cabinets, and having that digital information obscured from regulators will undermine our societal safeguards. Government agencies should already be acting to evaluate problematic AI-hiring software and seeking to uncover biases in models that determine who gets health interventions. As algorithmic decision-making becomes more common, it will be necessary to have a core of talented civic data scientists to audit their use in regulated industries.
Even for public servants who never write code themselves, it will be critical to have enough data science literacy to meaningfully interpret the proliferation of empirical research. Despite recent setbacks—such as proposed cuts to evidence-building infrastructure in the Trump administration’s budget proposal—evidence-based policymaking is not going anywhere in the long term. There are already 125 federal statistical agencies, and the Foundations of Evidence Based Policymaking Act, passed early last year, expands the footprint and impact of evidence across government programs.
“Even for public servants who never write code themselves, it will be critical to have enough data science literacy to meaningfully interpret the proliferation of empirical research.”
Further, the mindset of a data scientist is tremendously valuable for public servants: It forces people to confront uncertainty, consider counterfactuals, reason about complex patterns, and wonder what information is missing. It makes people skeptical of anecdotes, which, while often emotionally powerful, are not sufficient sources of information on which to build expansive policies. The late and lauded Alice Rivlin knew all this in 1970, when she published “Systemic Thinking for Social Action.” Arguing for more rigor and scientific processes in government decision-making, Rivlin wrote a pithy final line: “Put more simply, to do better, we must have a way of distinguishing better from worse.”
How to encourage data-scientific thinking and evidence-based policies
The tools and data to distinguish better from worse are more available than ever before, and more policymakers must know how to use and interpret them. A continued expansion of evidence-based decision-making relies on many individuals in many different roles, adopting practices that encourage data-scientific thinking. Managers in government agencies can hire analysts with a rigorous understanding of data in addition to a background in policy. They can also work to open up their datasets, contributing to Data.gov and the broader evidence-based infrastructure. Grant-making organizations have a critical role, too. They should be mandating an evaluation budget—at least 5% of a grant—to collect data and see if the programs they are funding actually work. When they fund research, it should require replicable research and open-data practices.
Related Content



For policy researchers looking to expand their sense of what is possible, keep an eye on the data science blogs at the Urban Institute and the Pew Research Center, which get into the weeds on how they are using emerging tools to build and disseminate new knowledge. And for current policy analysts who want to deepen their skills, they should consider applying to the Computational Social Science Summer Institute, a free two-week intensive to learn data skills in the context of social problems and policy data. Though much of it is not directly relevant to policy, there is a tremendous amount of online content for self-learners, too. I recommend looking into free online courses and learning to program in R. For those interested in a bigger investment, look to the joint data science and public policy graduate programs, like those at Georgetown University, the University of Chicago, and the University of Pennsylvania.
The Brookings Institution is a nonprofit organization devoted to independent research and policy solutions. Its mission is to conduct high-quality, independent research and, based on that research, to provide innovative, practical recommendations for policymakers and the public. The conclusions and recommendations of any Brookings publication are solely those of its author(s), and do not reflect the views of the Institution, its management, or its other scholars.
Google provides general, unrestricted support to the Institution. The findings, interpretations, and conclusions in this report are not influenced by any donation. Brookings recognizes that the value it provides is in its absolute commitment to quality, independence, and impact. Activities supported by its donors reflect this commitment.
Authors



